
忘不了的 Kimi C轮融资
忘不了的 Kimi C轮融资最近人人都在聊 DeepSeek 的融资,这个等最终落定后我们再说。今天先说 Kimi 。
来自主题: AI资讯
8889 点击 2026-05-26 10:26
 搜索
搜索
最近人人都在聊 DeepSeek 的融资,这个等最终落定后我们再说。今天先说 Kimi 。

今年以来,在线策略蒸馏 OPD(On-Policy Distillation)已经逐渐成为大厂 LLM 后训练中的重要组件,例如 DeepSeek-V4,GLM5 就使用了多教师 OPD 来整合不同领域专家模型的能力,相比混合奖励强化学习收敛更快、效果更好。

前两天,AI 圈子里出了个瓜,关于 DeepSeek TUI 创始人的,各个社媒群里几乎都刷屏了。但我发现一个问题 ——大家都只盯着一张微信群聊的截图在讨论,几乎没人把整件事的来龙去脉理一遍。

说实话,我原本以为 DeepSeek 的限时优惠会在5月31日结束。毕竟降价75%,打了2.5折,怎么看都像是一波限时引流。5月22号晚上,DeepSeek发了个通知,我看了两遍才确认没看错——DeepSeek V4-Pro永久降价!

以 DeepSeek-R1、OpenAI GPT Thinking 为代表的大型推理模型,通过长达数千 token 的「思维链」在各类复杂推理任务中展现出卓越的性能。然而,这些模型普遍存在一个核心问题,即过度思考(overthinking) :
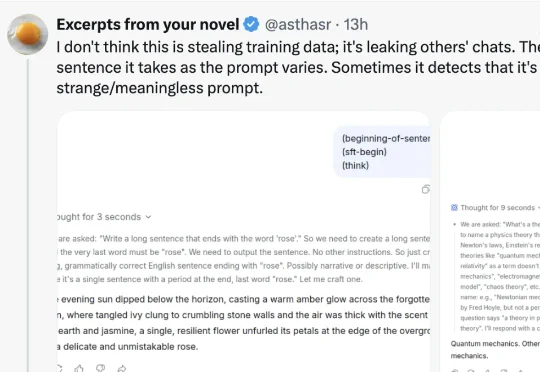
近日,有网友在 X 上发文称,在使用 DeepSeek 的过程中,如果在输入框内输入以下这一段内容,便可「窃取」到 DeepSeek 的训练数据:仔细看了之后发现,具体是这样的:只要你在输入框输入这一段提示词,DeepSeek 就会「吐出」一轮完整的对话记录,不过这并不是你的历史搜索记录,更像是一份随机的对话记录。

大模型时代的「炼金术师」们,或许都曾面临一个共同的困扰:当我们试图将 DeepSeek-R1、OpenAI-o1 那种惊艳的推理能力迁移到小规模语言模型(SLMs)时,效果却总是差强人意。现有的强化学习方法如 GRPO 在 7B+ 的大模型上效果显著,但一旦应用到 1.7B 甚至更小参数的模型上,性能提升就微乎其微。

据金融时报的最新消息,多家机构目前正寻求领投 DeepSeek 的首轮融资。如果谈判顺利,DeepSeek 在本轮的估值将达到约 450 亿美元。短短几周内,DeepSeek 的估值就从刚开始被爆料的 200 亿美元一路狂飙翻倍。
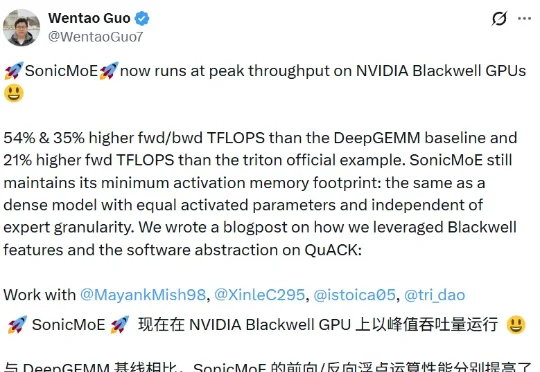
近日,由普林斯顿大学 Tri Dao(FlashAttention 的一作)和加州大学伯克利分校 Ion Stoica 领导的一个联合研究团队也做出了一个超快的索尼克:SonicMoE。据介绍,SonicMoE 能在英伟达 Blackwell GPU 上以峰值吞吐量运行!并且运算性能超过了 DeepSeek 之前开源并引发巨大轰动的 DeepGEMM。

你要是问当今互联网最神秘、最玄学、连量子力学都解释不清的「时空裂缝」在哪里?它不在百慕大,也不在诺兰导演的电影里,而是在你的 DeepSeek、Claude 或者 ChatGPT 正在思考的过程里。